

I recently returned from a trip to San Francisco. While there, I presented to the innovation group of a large insurance company about how startups are applying AI.
This post shares that presentation I gave. In addition to the written presentation, I've recorded an audio version of it here, too.
Listen to a recording of the presentation on Apple Podcasts, Spotify, Overcast, Pocket Casts, Castbox, Google Podcasts, Amazon Music, or many other players.

We all know that ChatGPT can write essays, suggest travel itineraries, and draft emails. These tasks are powerful, but only scratch the surface of what LLMs can do.
In the past year, a wave of startups has emerged, leveraging AI to rethink industries ranging from software development to operations to marketing. These companies are building entirely new categories of AI-driven tools, seeking to disrupt current businesses.
In this presentation, I’ll explore the emerging archetypes of LLM-powered apps: the core techniques, architectures, and approaches shaping the next generation of products.
I’m Philip, and I write a blog called Contraption Company. For the past two years, I've been the CTO of Find AI, a startup building a search engine for people and companies. We’re pushing OpenAI’s technology to its extremes—making over one hundred million requests this year alone—and uncovering innovative ways to apply its power. Today, I’ll share some of those lessons and ideas with you.

By the end of this presentation, my goal is for you to understand how businesses are applying LLMs in practice. With this toolkit of patterns, you’ll be able to identify opportunities in your own company to improve efficiency with LLMs and decide whether it makes sense to build or buy solutions.

Well go through three parts in this presentation, from basic to advanced.
In part one, we'll review building block technologies - like chat, embeddings, semantic search, fine tuning, and some non-LLM tools.
In part two, we'll look at basic applications of LLMs that power most startups - such as code generation, text to SQL, summarization, advanced moderation, text generation, analysis, intent detection, and data labeling.
In part three, we'll review advanced applications of LLMs that represent more frontier applications: retrieval-augmented generation (RAG), agents, and swarms.

First, let's review foundational "building block" technologies that power LLM apps.
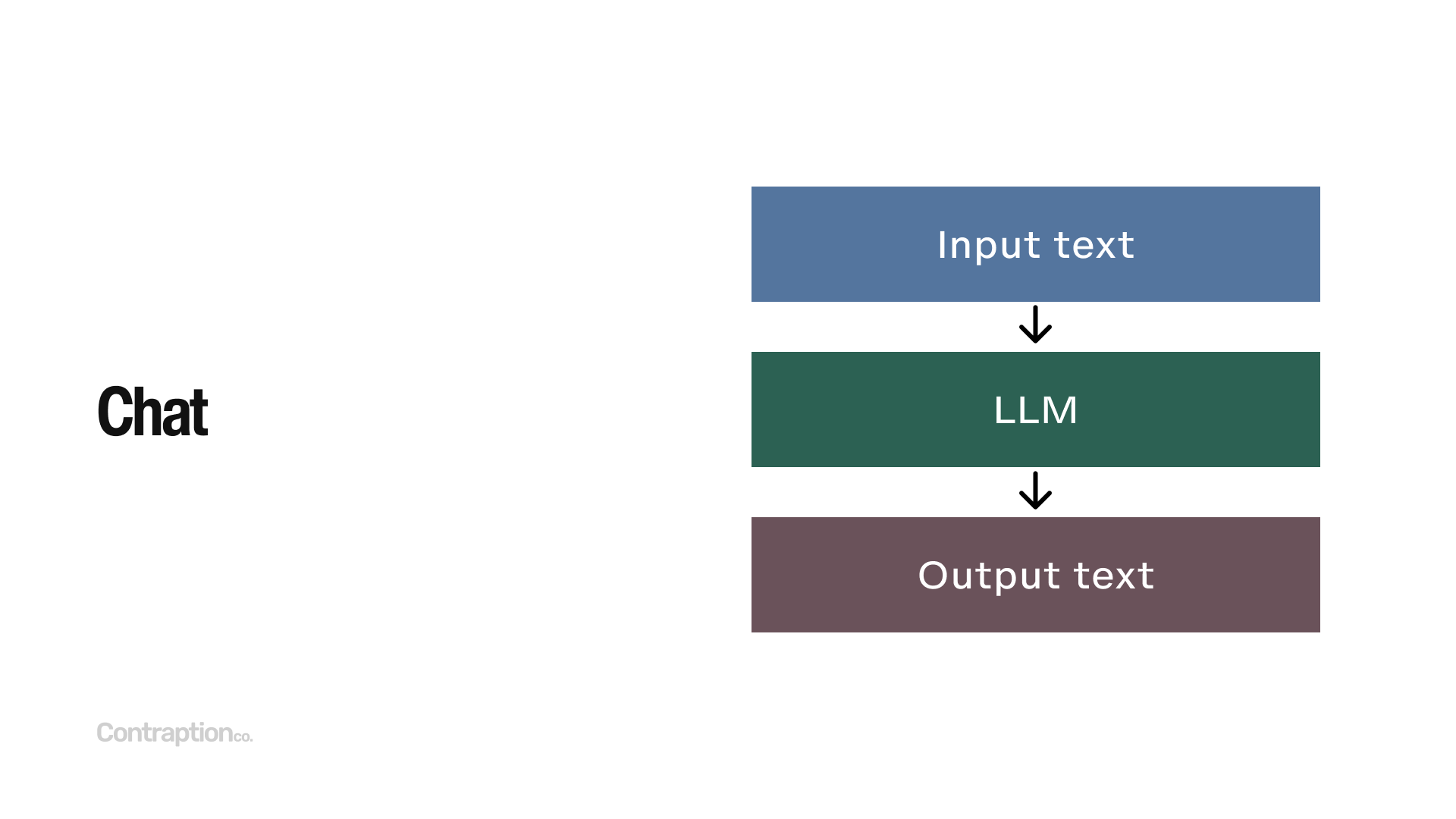
Chat lies at the heart of most LLM applications. As we review advanced techniques like “intent detection” and “retrieval-augmented generation,” the underlying interface is still chat: input text is processed by an LLM, which generates output text.
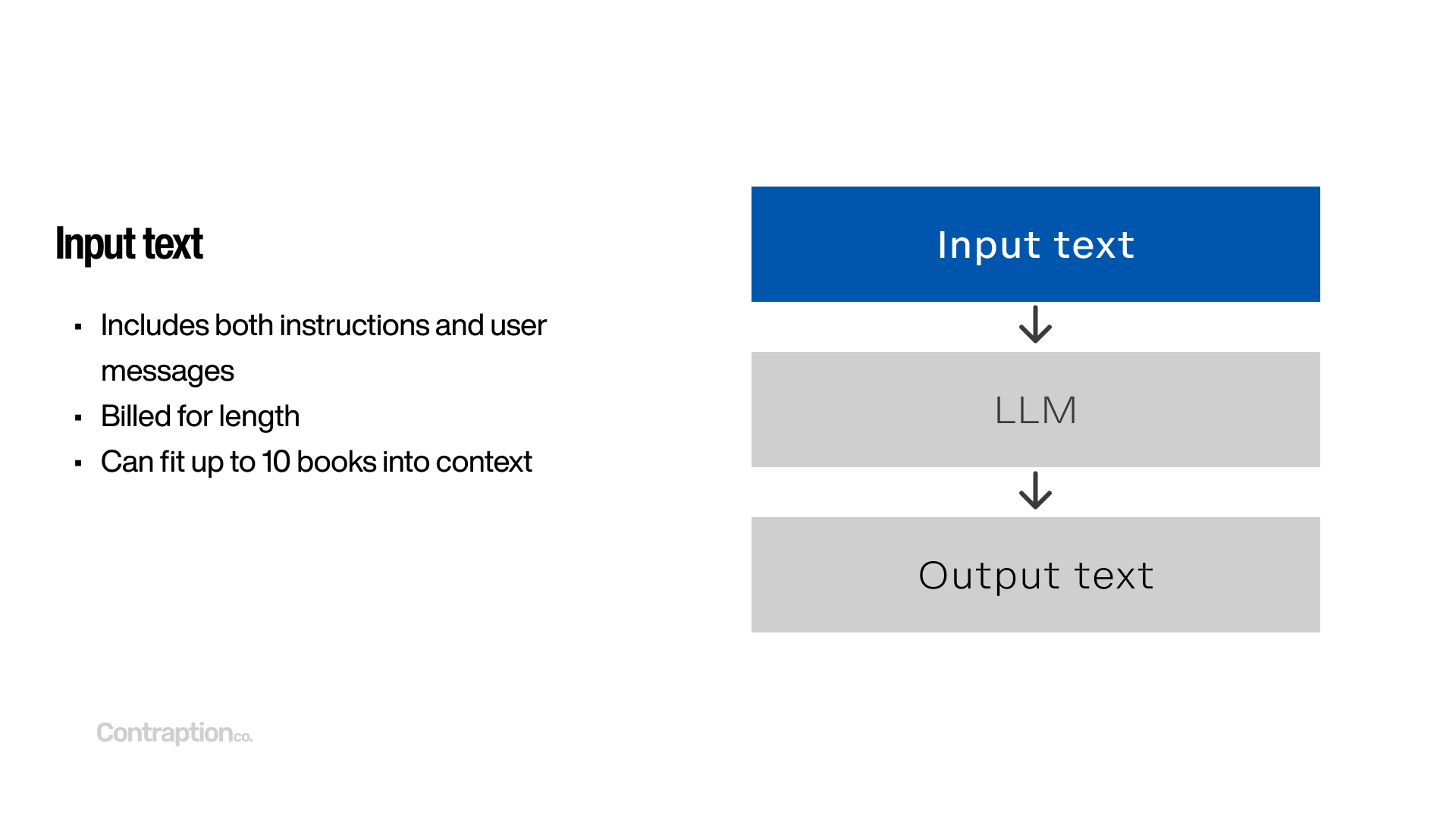
Input text typically consists of both instructions and user-provided data. Hosted model providers like OpenAI and Anthropic charge for the length of the input text, which is measured in “tokens.” The size of the input text varies by model.
Currently, Google’s Gemini 1.5 Pro model offers the largest input capacity, handling up to 2 million tokens—roughly equivalent to the text of 10 books. For example, it can process the entire Harry Potter series in its input and perform tasks like generating a chapter-by-chapter summary of the spells used. However, it’s important to note that recall isn’t perfect, and including large volumes of context can sometimes reduce performance.

The primary models in use today are OpenAI’s GPT-4o, Anthropic’s Claude, and Meta’s LLaMA. All of these models generally offer comparable performance.
Smaller, more cost-efficient models, such as GPT-4o-mini, are also available. These require less computational power, enabling higher throughput on the same hardware. As a rule of thumb, these "mini" models typically cost about 1/10th as much as standard models, but are less accurate.
LLMs include a “temperature” parameter that developers can adjust for each request. This parameter controls the randomness of the output: higher temperatures produce more creative responses, while lower temperatures yield more predictable results.
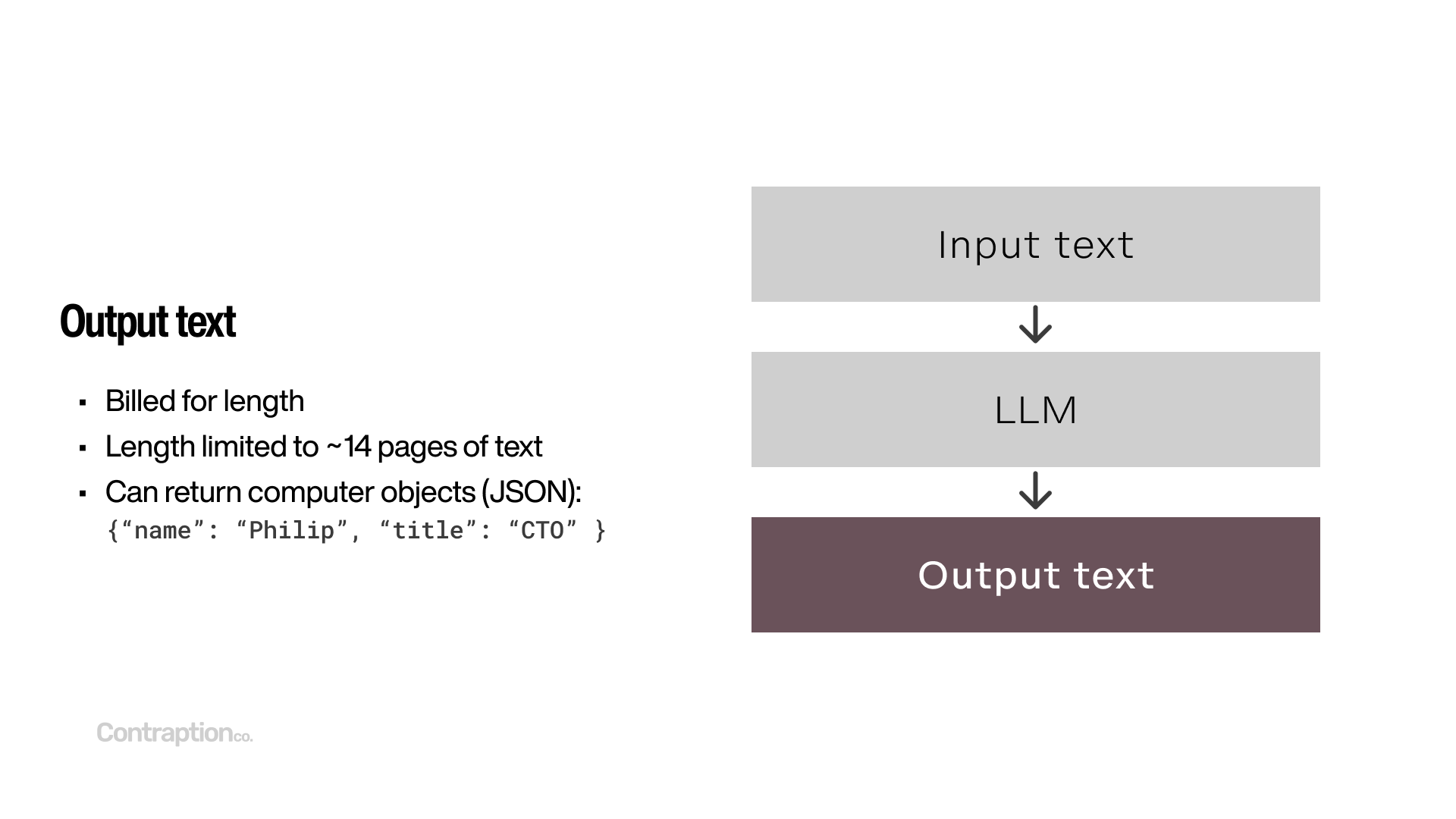
LLMs output text. Hosted providers charge for the length of the output text. But, most output text is limited to about 14 pages of text. So, output length tends to contribute far less to overall costs than the input length.
While we typically think of output from LLMs as plain text sentences, they can also return structured data using formats like JSON. Providers such as OpenAI have introduced tools to enforce specific output formats, ensuring reliability and accuracy. This capability allows you to transform unstructured data into structured formats or request multiple data points in a single call, streamlining tasks that would otherwise require separate queries.
Among the major model constructors today, OpenAI and Anthropic provide hosted solutions, where the companies manage the infrastructure, and you pay per request. In contrast, Meta’s LLaMA is open-source, giving you the flexibility to run it on your own servers.
Based on our experience using OpenAI’s GPT-4o at Find AI, a useful mental model is that a typical LLM call costs around one cent, assuming standard input and output sizes. However, if you process a large amount of data—such as the full text of all the Harry Potter books—the cost can rise to approximately $2.50 per call.
Hosted model providers offer enterprise-grade support. For example, Microsoft can deploy a dedicated instance of an OpenAI model for you, ensuring privacy, HIPAA compliance, and other enterprise requirements.
Self-hosting a model involves significant complexity, requiring you to forecast capacity, deploy and manage servers, and optimize request routing. Due to these challenges, many businesses rely on vendors to handle these tasks, further blurring the line between hosted and self-hosted models.
For context, one H-100 GPU, often considered the workhorse for high-performance AI workloads and recommended for models like LLaMA, typically costs around $2,500 per month on a cloud provider.

The next building block is embeddings. Embeddings are algorithms used in LLM applications, though they are not themselves LLMs. They convert text into numerical representations that capture its underlying meaning, enabling us to measure the relatedness of text using mathematics.
Embedding algorithms transform text into vectors, which are essentially points in a multi-dimensional space. These vectors encode meaning as a series of numbers, allowing us to determine how similar two pieces of text are based on their proximity in this space.
OpenAI offers some of the most advanced embedding algorithms available today. Their most advanced model returns 3,072-dimensional vectors, can process inputs in multiple languages, and are widely used to extract and compare textual meaning. However, there are many different embedding algorithms, and it’s crucial to use the same algorithm consistently across your text for accurate results.
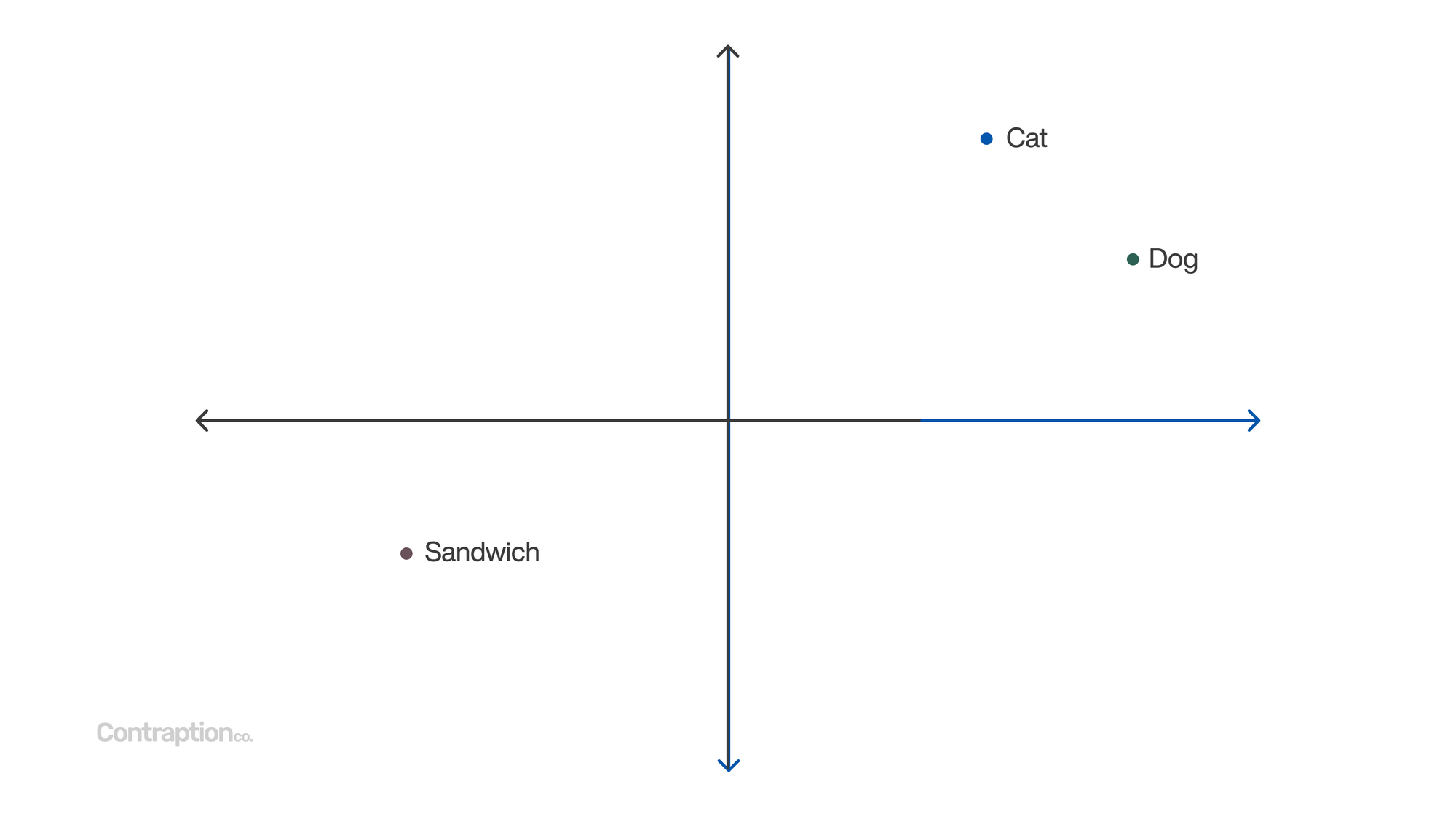
By measuring the distance between points, we can determine how closely related different concepts are. For example, “cat” and “dog” are closer to each other than “sandwich,” reflecting their greater similarity in meaning. LLM applications leverage embeddings to enable searches based on semantic meaning rather than just keywords.

Historically, search applications have relied on keyword-based approaches to find relevant text. Tools like Elasticsearch and Algolia use this traditional method, often employing algorithms such as Levenshtein distance to measure relatedness. This approach works well for locating exact or similar keywords—for example, searching “dog breeds” might return “list of dog breeds.” However, it might miss relevant results like “poodles” and mistakenly include irrelevant ones like “hot dog ingredients.”
Semantic search represents a new generation of search technology, widely used in LLM applications. Instead of focusing on keywords, it evaluates meaning by measuring the cosine distance between embedded vectors. With semantic search, a query like “dog breeds” would correctly identify “poodles” as relevant while excluding “hot dog ingredients.”
As you explore LLM applications, it’s important to understand that semantic search is a foundational technology powering many of them.

As semantic search becomes integral to many LLM applications, specialized databases for storing and searching vectors are gaining traction. Some options, like pgvector, are free and open source, serving as an extension to the widely used PostgreSQL database. Others, such as Pinecone and Milvus, are standalone vector databases designed specifically for this purpose.
Storing vectors can be resource-intensive because they don’t compress well, and maintaining fast search speeds requires computationally expensive algorithms.
At Find AI, we initially implemented semantic search using pgvector alongside our application data. However, we found that 90% of our disk space and 99% of our CPU were consumed by vector calculations, resulting in slow performance. Eventually, we transitioned to Pinecone's managed vector database optimized for this workload. While it significantly improved performance, it also became more expensive than our primary application database.
A takeaway is that there are infrastructure costs to running LLM applications beyond the LLMs themselves, and these can be substantial.

Fine-tuning is an important concept in working with LLMs. It allows you to take a pre-trained model and further train it for your specific use case. This can be done with both hosted and self-hosted models. One common approach is to fine-tune a less expensive model to perform a specific task at a level comparable to a more costly model.
However, fine-tuning comes with significant trade-offs. The process is often slow and expensive, and it can be difficult to assess whether fine-tuning has introduced negative impacts on the model’s performance in other areas. For these reasons, I typically recommend avoiding fine-tuning until you have a mature AI program. It’s better thought of as a scaling tool rather than a starting point for developing AI applications.

As the final part of the “Building Blocks” section, I want to highlight a few tools provided by Anthropic and OpenAI that, while not LLMs themselves, can play an important role in LLM applications.
Moderation: Both OpenAI and Anthropic offer advanced moderation APIs that can review text and flag potential safety issues. These tools are sophisticated enough to differentiate between nuanced phrases like “I hope you kill this presentation” and “I hope you kill the presenter.” Many LLM applications integrate these moderation endpoints as a preliminary step before executing application logic.
Voice: Speech-to-text and text-to-speech technologies have become quick and reliable, enabling most text-based applications to be seamlessly adapted into voice-based ones. It’s worth noting, however, that most voice-driven LLM applications work by first converting voice to text and then using the same text-based LLM tools discussed here. Essentially, it’s just a different user interface.
Image generation: Image generation has advanced significantly and is a powerful tool often used alongside LLMs. While not directly powered by LLMs, it complements many AI-driven applications, expanding their functionality.
Batch processing: Hosted model providers like OpenAI offer discounts—up to 50% —if you allow a 24-hour turnaround for requests instead of requiring immediate responses. This can be particularly useful for background tasks, such as data analysis. By taking advantage of batch processing, you can dramatically lower costs, especially for tasks that don’t need real-time results.

Next, we'll review some basic LLM applications.

The first major archetype of LLM applications is code generation. LLMs excel at tasks ranging from generating basic functions to making contextual modifications across multiple files and even building full-stack features. By analyzing multiple files as input, these models can maintain consistency and streamline development workflows.

The most prominent tool in this space is Microsoft’s GitHub Copilot, with over one million paying customers. Another example is Cursor, a code-writing tool with integrated AI capabilities that can generate code, develop features, and perform semantic search across codebases. It’s incredible. Even Google reports that 25% of its new code is already being written by AI.
AI-powered code generation has brought a step-function increase in productivity, making it an essential tool for developers. As one CTO of a billion-dollar company told me, “Developers who haven’t adopted AI are now considered low-performers.” While we’ll explore various startups and tools in this presentation, I want to emphasize that AI is no longer a “future” tool in software development—it’s already the standard.

A notable category of code generation is text-to-SQL. AI excels at generating database queries, making it possible for even non-technical users to eailiy ask questions from data stores and warehouses. LLM models can analyze available data structures, including tables and columns, and generate complex, advanced queries. I rely heavily on AI for SQL queries, and there have been instances where it produced queries I initially thought were impossible.
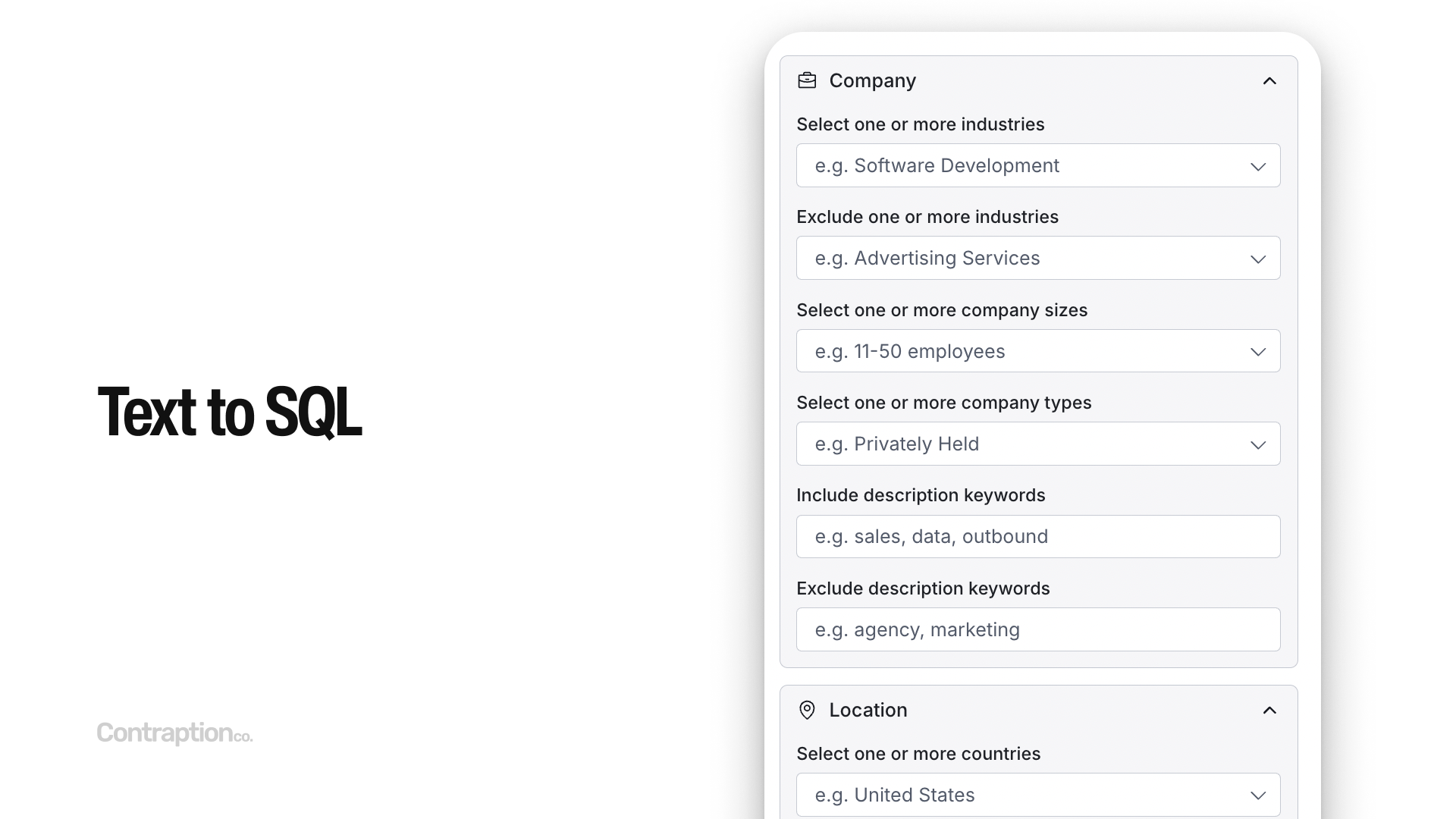
Text-to-SQL can even improve customer-facing applications. Traditional filter interfaces—commonly used to narrow data in tables via dropdowns, typeaheads, and tags—are a staple of CRMs, customer support tools, and similar platforms. These interfaces work by generating SQL queries behind the scenes to retrieve results.
With AI, these cumbersome filter-based UIs are being replaced by natural language input. Users can now enter queries like “Companies in the USA with 50-100 employees,” and the AI automatically generates the appropriate SQL query, eliminating the need for complex and bloated interfaces.

Summarization is one of the core strengths of LLMs. By providing text, you can receive concise, high-quality summaries. Summarizations can also be structured, such as condensing a news article into a tweet or transforming a historical article into a timeline.
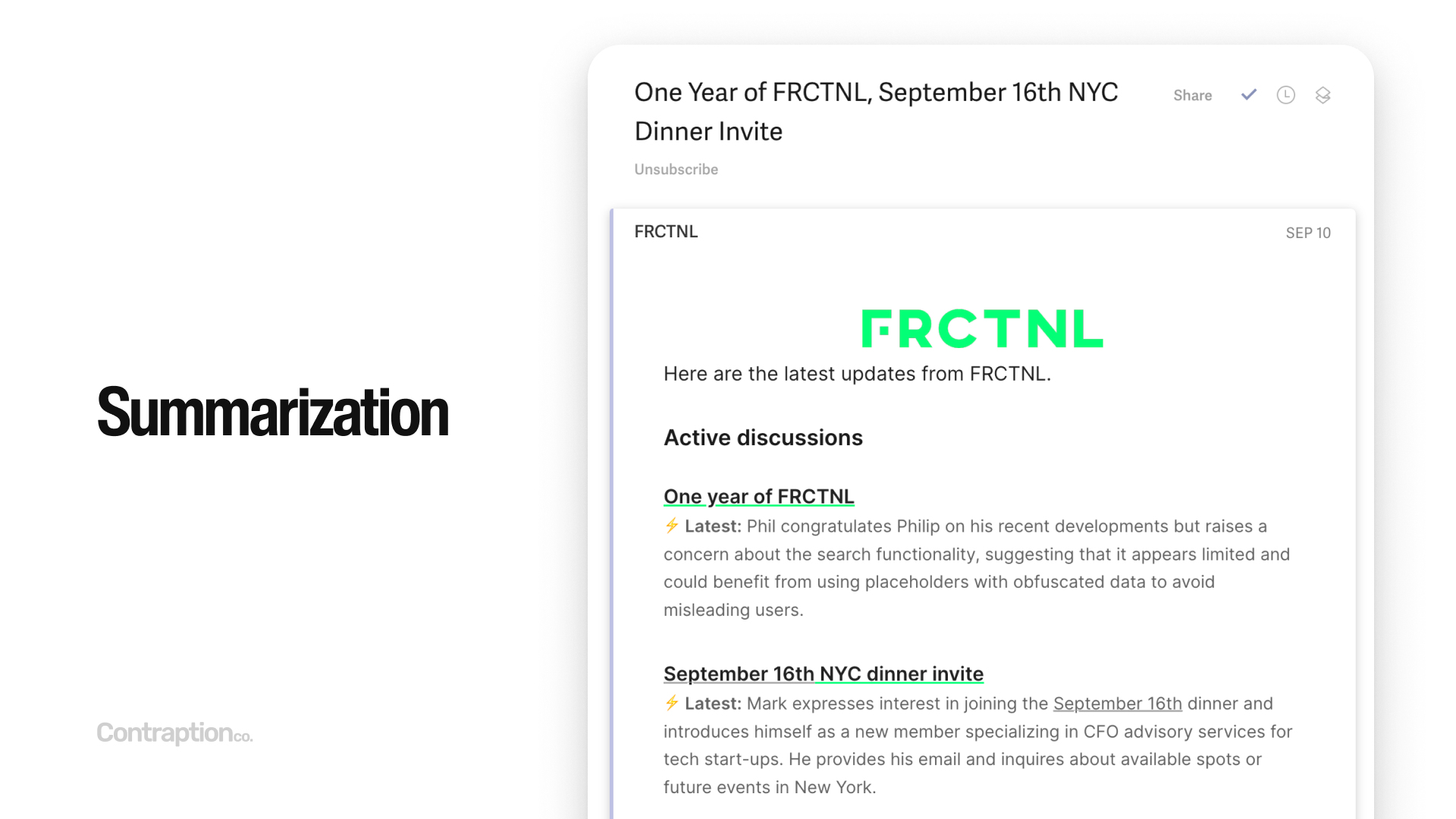
Here’s an example of an email newsletter created using my software, Booklet. It analyzes new posts and discussions in a community and generates all the content automatically. The subject line, titles, and summaries in the email are all generated by AI. This newsletter is sent to thousands of people daily—completely automated, with no human intervention.

Earlier, I mentioned that model providers offer free safety-focused moderation tools. However, LLMs can also be leveraged to build more advanced, rule-based moderation systems. For example, in a customer support forum, you can provide the community rules to an LLM and have it review posts to ensure compliance. These automated community management systems are quick and reliable.
Interestingly, most moderation applications also prompt the LLM to provide a reason for its judgment. Asking the model to explain its decisions not only adds transparency but often improves its accuracy.

The next archetype is text generation, where LLMs excel at creating new content. One particularly effective use case is combining two existing documents into a cohesive new one. For instance, if you have a document titled “How to File a Reimbursement” and another titled “How to Add Your Child to Your Account,” you can prompt an LLM to generate a new article, such as “How to File a Reimbursement on Behalf of a Child.”
Text generation is a key feature in many marketing startups. For example, LoopGenius leverages LLMs to automatically generate, test, and refine Facebook ads. Tools like Copy.ai and Jasper focus on creating content for marketing pages, helping businesses improve their SEO strategies.
However, AI-generated content is flooding the internet. It’s now easier than ever for companies to add millions of pages to their websites, leading to an oversaturation of material. As a result, it’s likely that Google will adapt its algorithms to address the proliferation of AI-driven content.

The next archetype is analysis, where LLMs can evaluate data and provide decisions. For example, you can ask ChatGPT to compare a job description and a resume to analyze whether a candidate is a good match for the role—and it performs this task remarkably well.

At Find AI, we also leverage analysis. When you run a search like “Startup founders who have a dog,” the system asks OpenAI to review profiles one by one and determine, “Is this person a startup founder who has a dog?”
Currently, recruiting is one of the most common use cases for analysis. Many companies rely on AI for initial applicant screening, significantly streamlining the hiring process. Applicant AI is one example, but many similar tools are emerging in this space.

Intent detection is one of my favorite applications of LLMs. We’ve all encountered traditional phone menus that say, “Press 1 for new customer enrollment, press 2 for billing, press 3 for sales,” and so on. AI can replace this process by simply asking, “Why are you calling?” and then routing the caller to the appropriate department. This technique, where AI maps a user’s input to a predefined set of options, is known as intent detection.
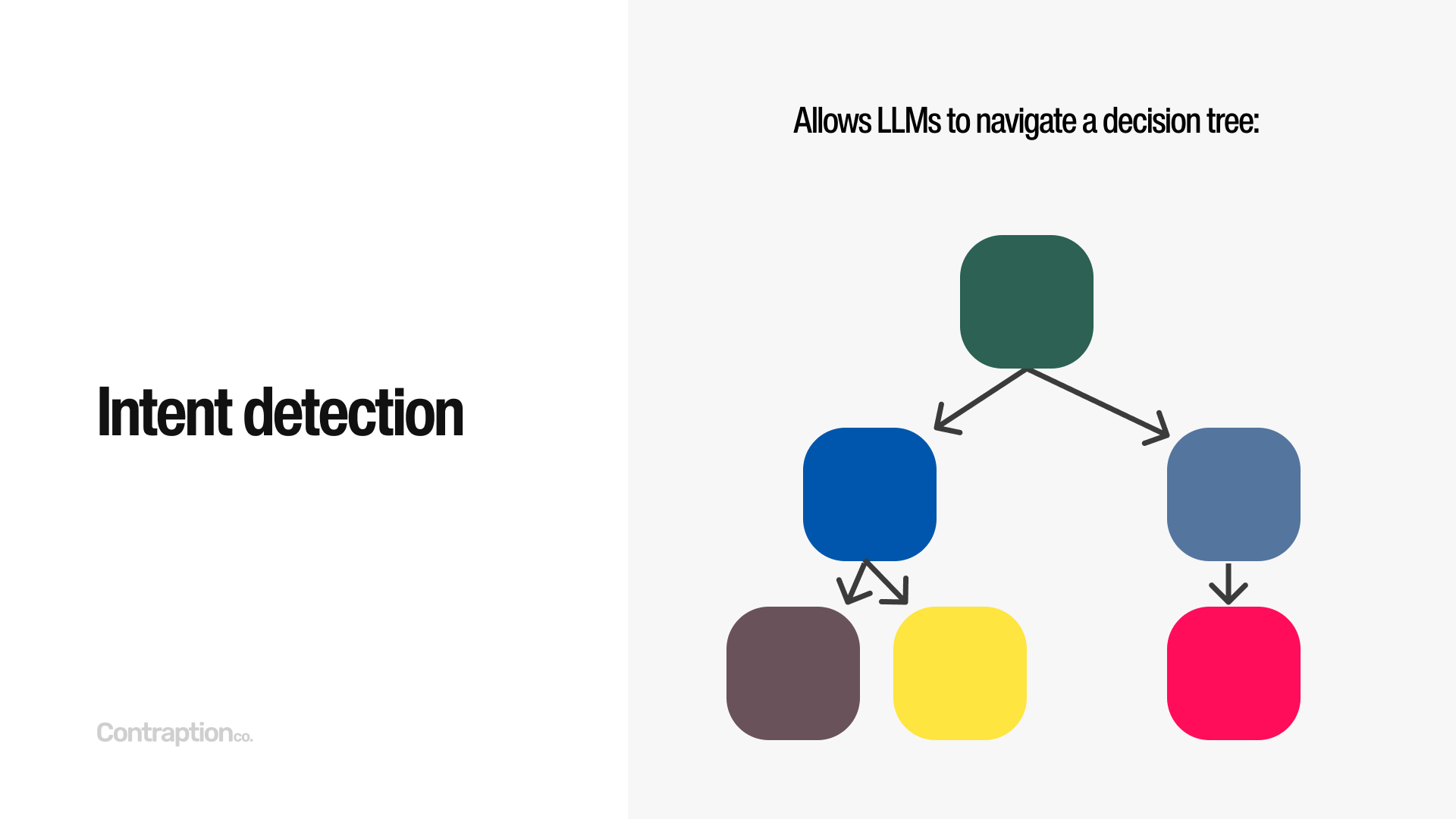
Intent detection is a foundational technique widely used in more advanced AI applications because it enables systems to navigate decision trees. Many customer interactions are essentially a series of decisions, and LLMs can make these processes feel seamless by converting them into natural language exchanges. At Find AI, for example, every search begins with an intent detection step, where we ask the LLM, “Is this query about a person or a company?”

Call centers have been early adopters of intent detection, integrating it into customer support and sales workflows. Companies like Observe AI and PolyAI are reimagining these functions with solutions that blend the strengths of LLMs and human agents.

LLMs are increasingly being used in analytics for data labeling, a critical task in tools like customer support and sales systems. Tags and labels help track things like feature requests or objections, tasks that previously required customer support agents to spend significant time manually tagging conversations. Now, LLMs can automate this process entirely.
This capability is particularly useful for analyzing historical data. For example, you could instruct an LLM to review all past customer conversations and identify instances where a company requested an API.
At Find AI, we use LLMs to label every search after it’s run, applying tags like “Person at a particular company” or “Location-based search.”
Data labeling also pairs well with the Batch processing capability discussed earlier. By allowing up to 24 hours for a response, you can significantly reduce costs while efficiently processing large volumes of data.

Building LLMs required massive amounts of human-labeled data, leading to the rise of companies over the past decade that specialize in data labeling, such as Scale AI and Snorkel AI. Interestingly, many of these tools, which were once entirely human-driven, have now evolved to incorporate both AI and human-based labeling systems. As a result, there is now a robust ecosystem of reliable tools available for data labeling, combining the efficiency of AI with the precision of human input.

In the final section, we’ll explore advanced applications of LLMs, focusing on complex and cutting-edge techniques at the forefront of AI development.
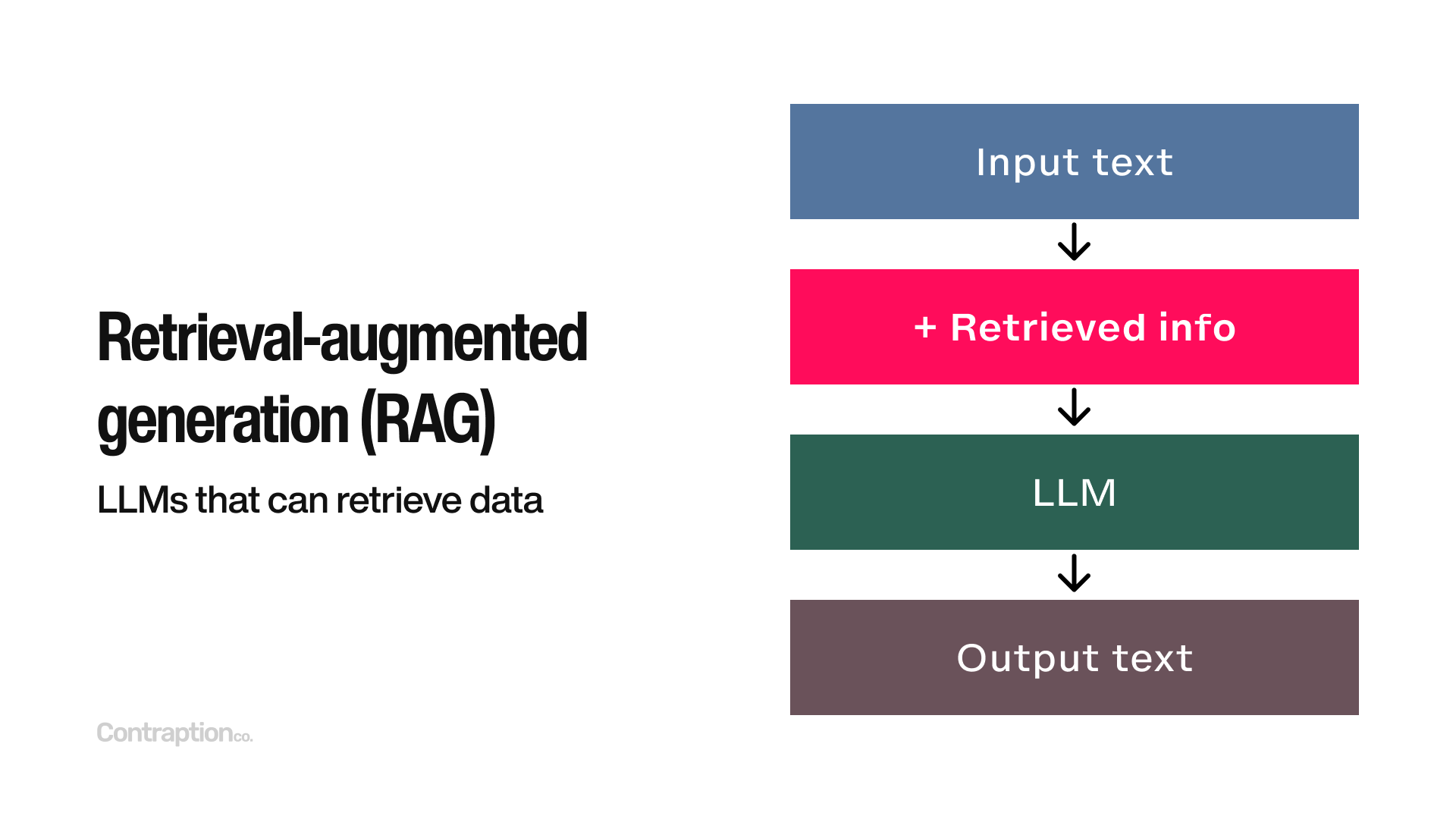
The first advanced technique we’ll cover is retrieval-augmented generation (RAG). This approach enables an LLM to retrieve relevant information to improve its responses. After a user inputs a query, the LLM retrieves specific data, feeds it into the model, and generates a more accurate output.
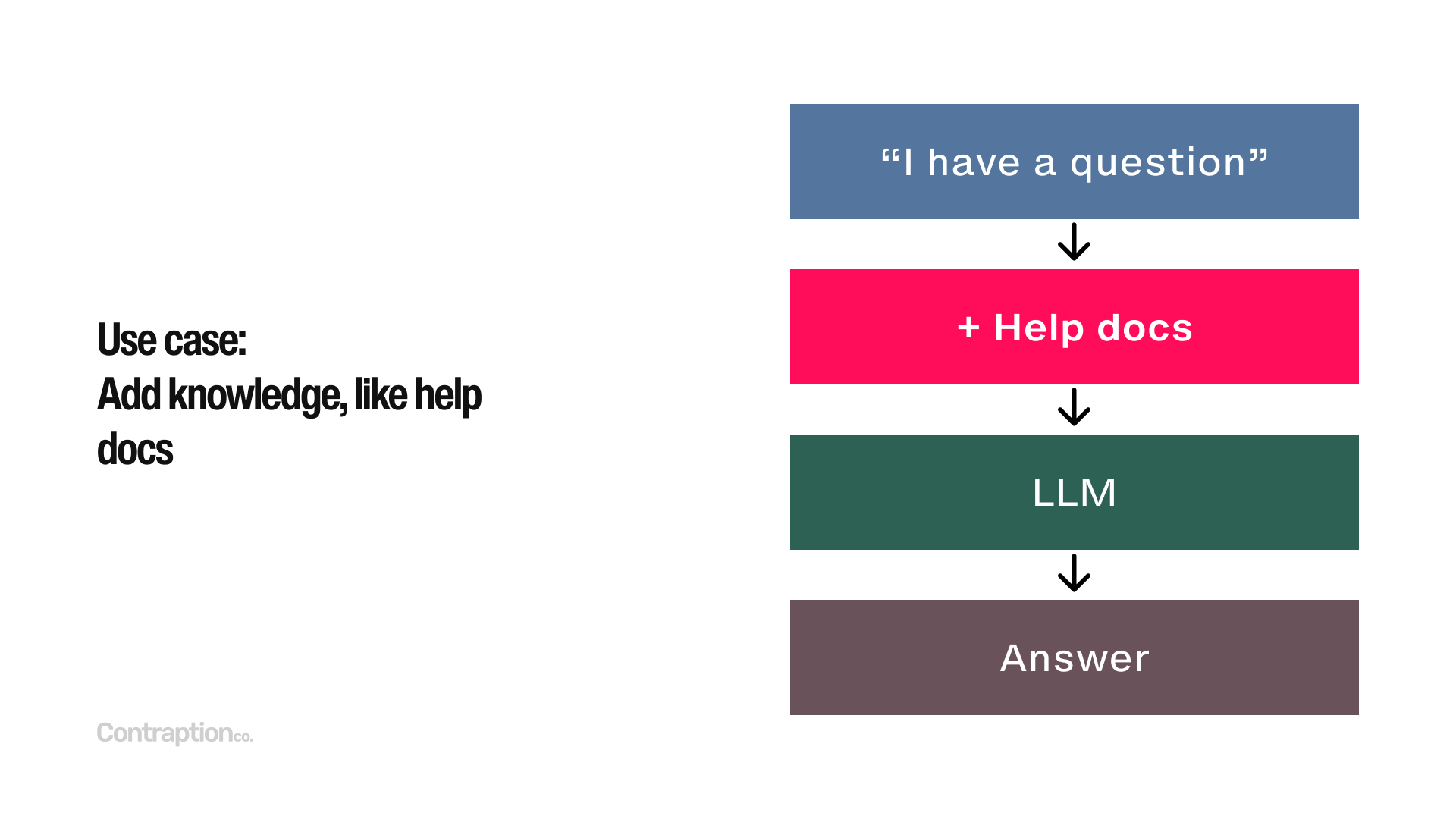
A common use case for RAG is improving help documentation. For example, if a user asks, “How do I submit an expense report?” we want the LLM to access relevant documents about expense reporting to provide the correct answer. However, including all help docs in every query would be prohibitively expensive, and overwhelming the context with too much information could decrease accuracy.

The goal of RAG is to retrieve and include only the most relevant documents—perhaps two or three—to assist with the query. This is achieved using the foundational technologies of embeddings and vector databases
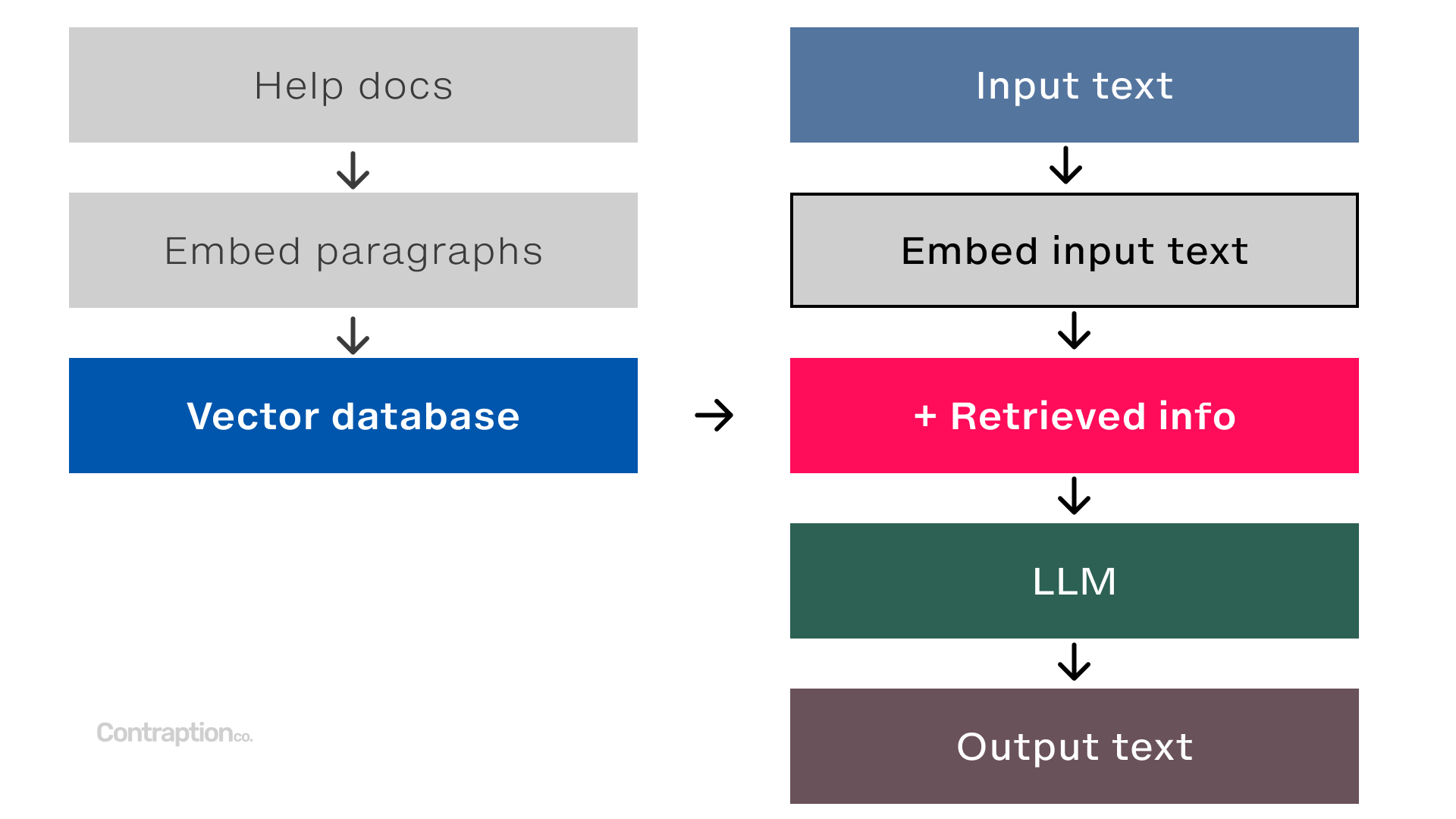
Here’s how most RAG applications work: beforehand, all data (such as help docs) is broken down into smaller chunks, like paragraphs. Each chunk is embedded and stored in a vector database. When a user asks a question like “How do I file an expense report?” the system retrieves only the most relevant articles from the database. By feeding this targeted information into the LLM, RAG enhances the response.
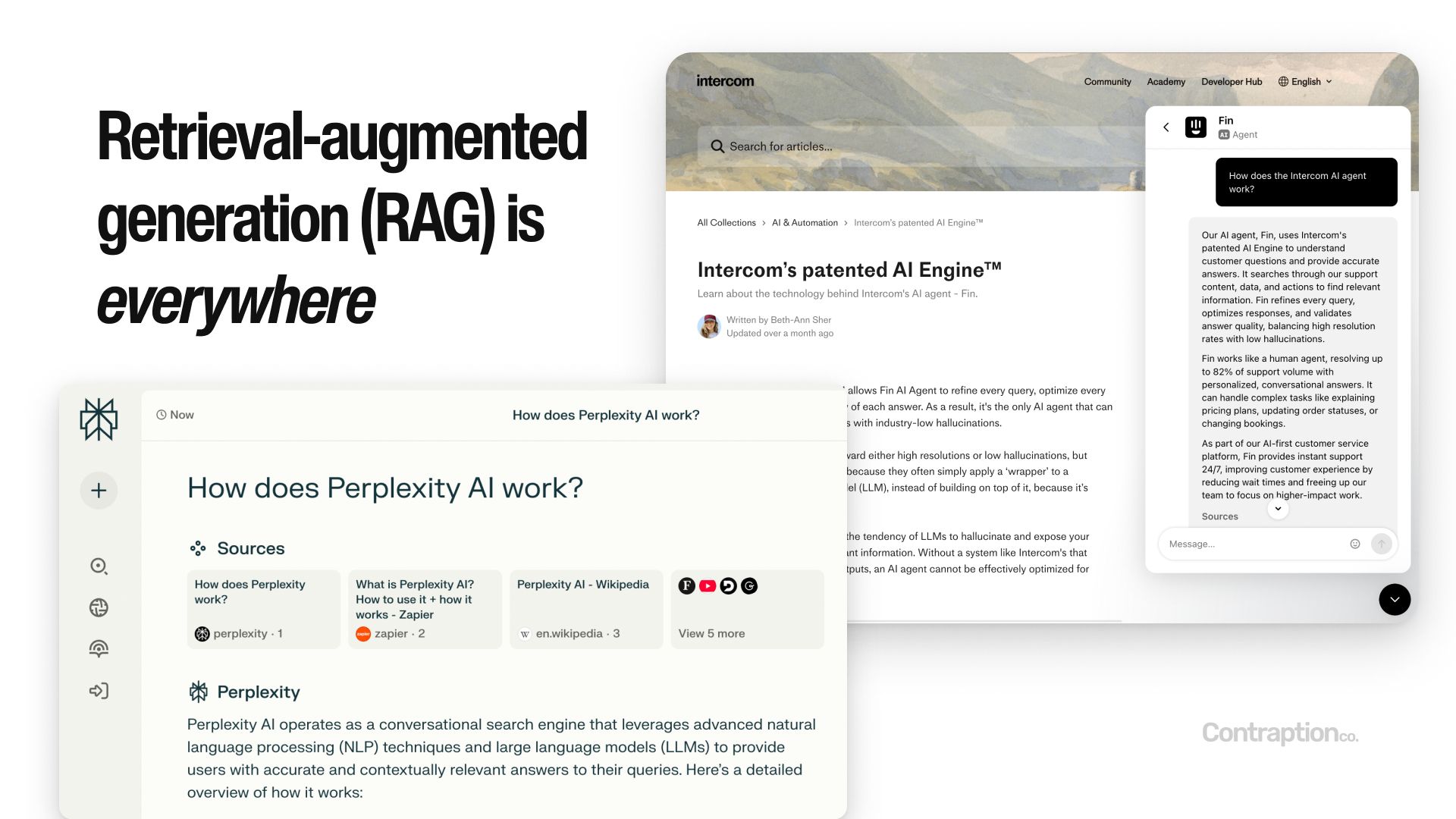
RAG is foundational to many LLM applications today because it allows companies to incorporate unique, business-specific information into responses while keeping costs manageable. This technique is already widely used in customer support tools, such as Intercom’s chatbots, and powers other AI-driven applications like Perplexity AI.
In many ways, RAG is the core method businesses use to tailor AI systems to their specific logic and needs.
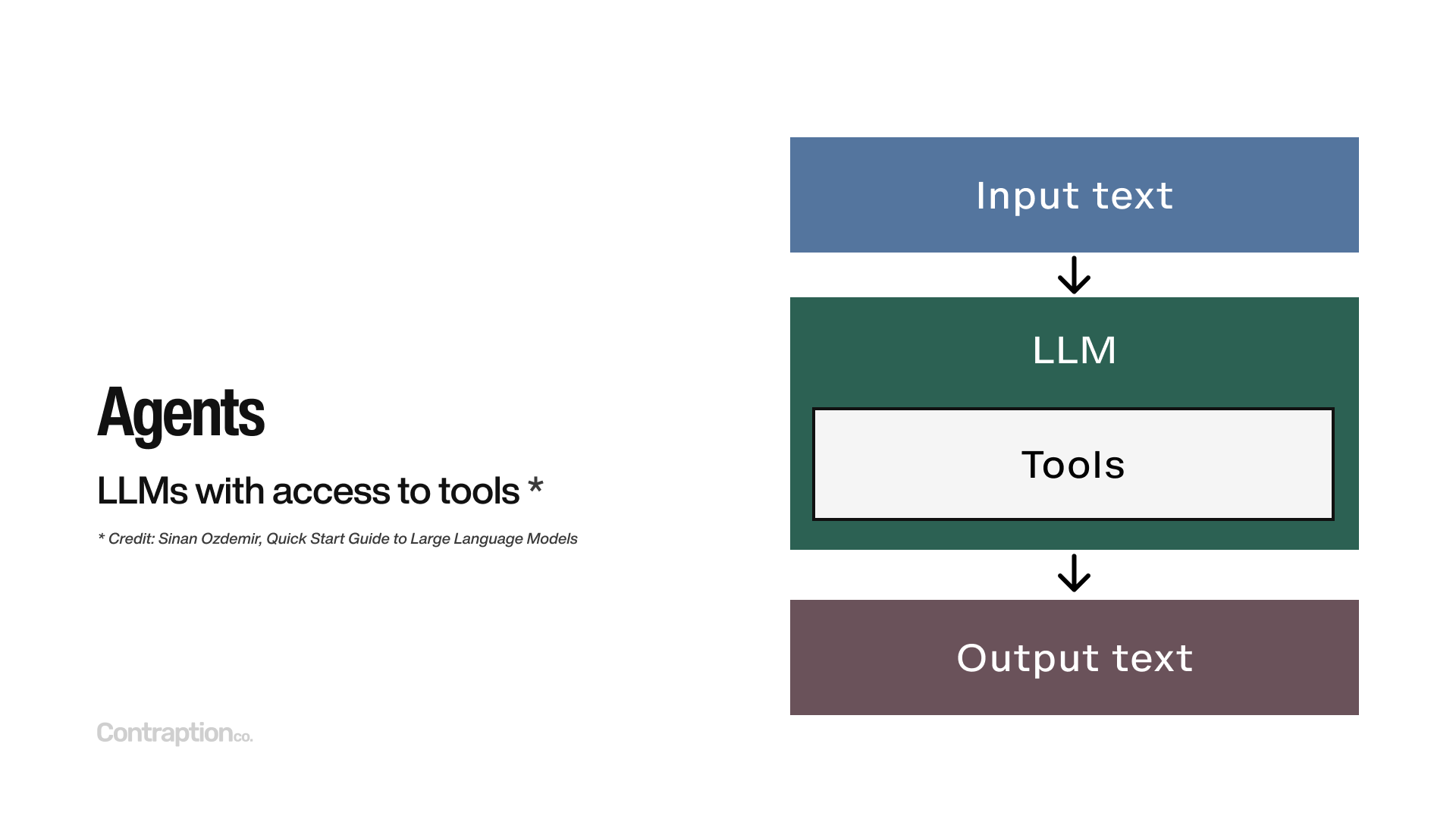
The next advanced technique is Agents, which have become a hot topic in the AI space. If you visit a startup accelerator today, you’ll likely find a dozen startups touting their agent-based solutions, many of them raising millions in funding.
The definition of an agent remains somewhat fluid, but I like the one from the Quick Start Guide to Large Language Models: an agent is an LLM with access to tools. These tools define the agent’s functionality and can, in theory, be anything.
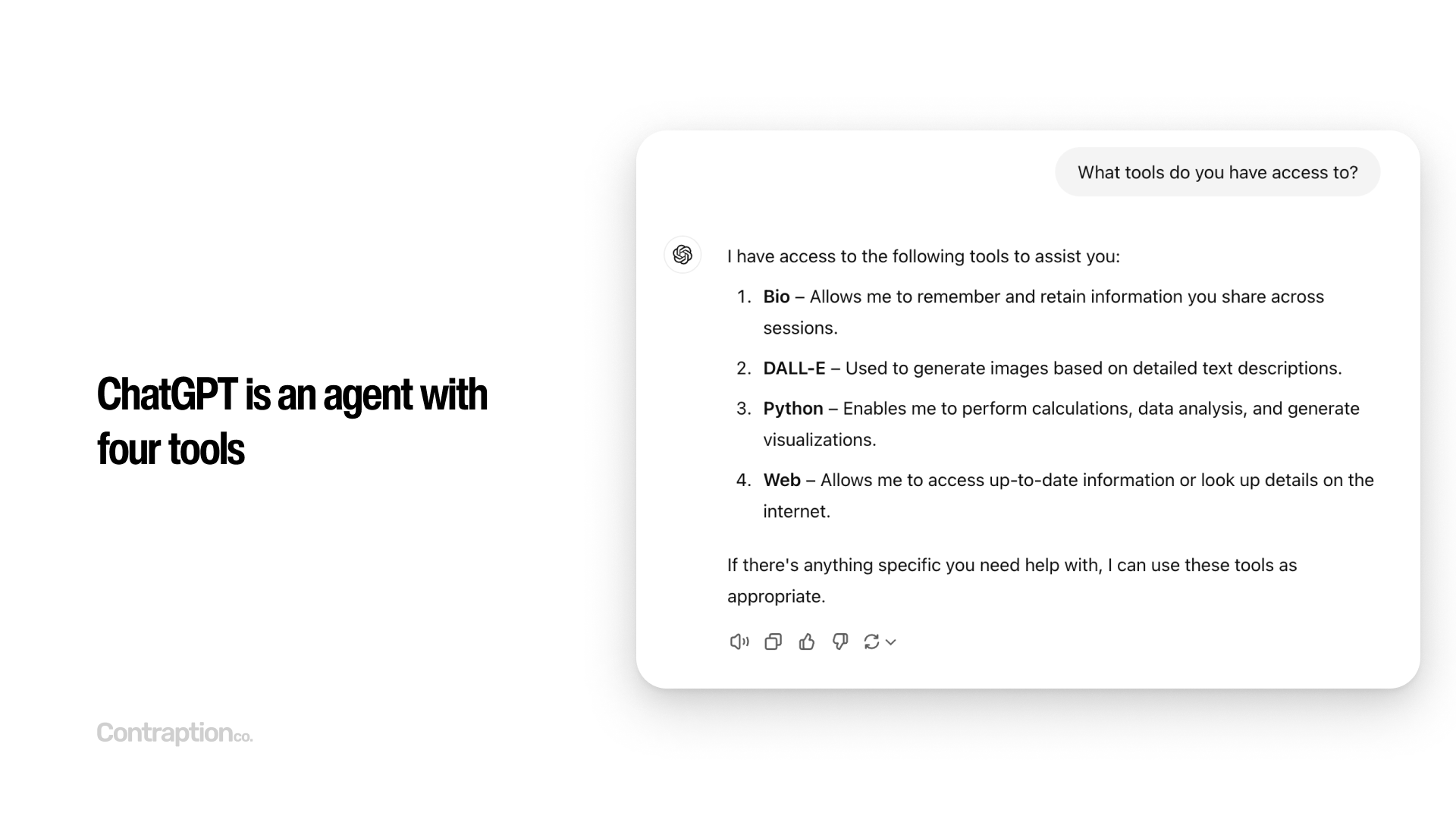
The most popular agent today is ChatGPT. If you ask ChatGPT about the tools it has access to, it will list: Bio for memory, DALL-E for image generation, Python for executing code, and Web for internet searches. This is also the key difference between ChatGPT and the OpenAI API: these four tools are not available to API users.
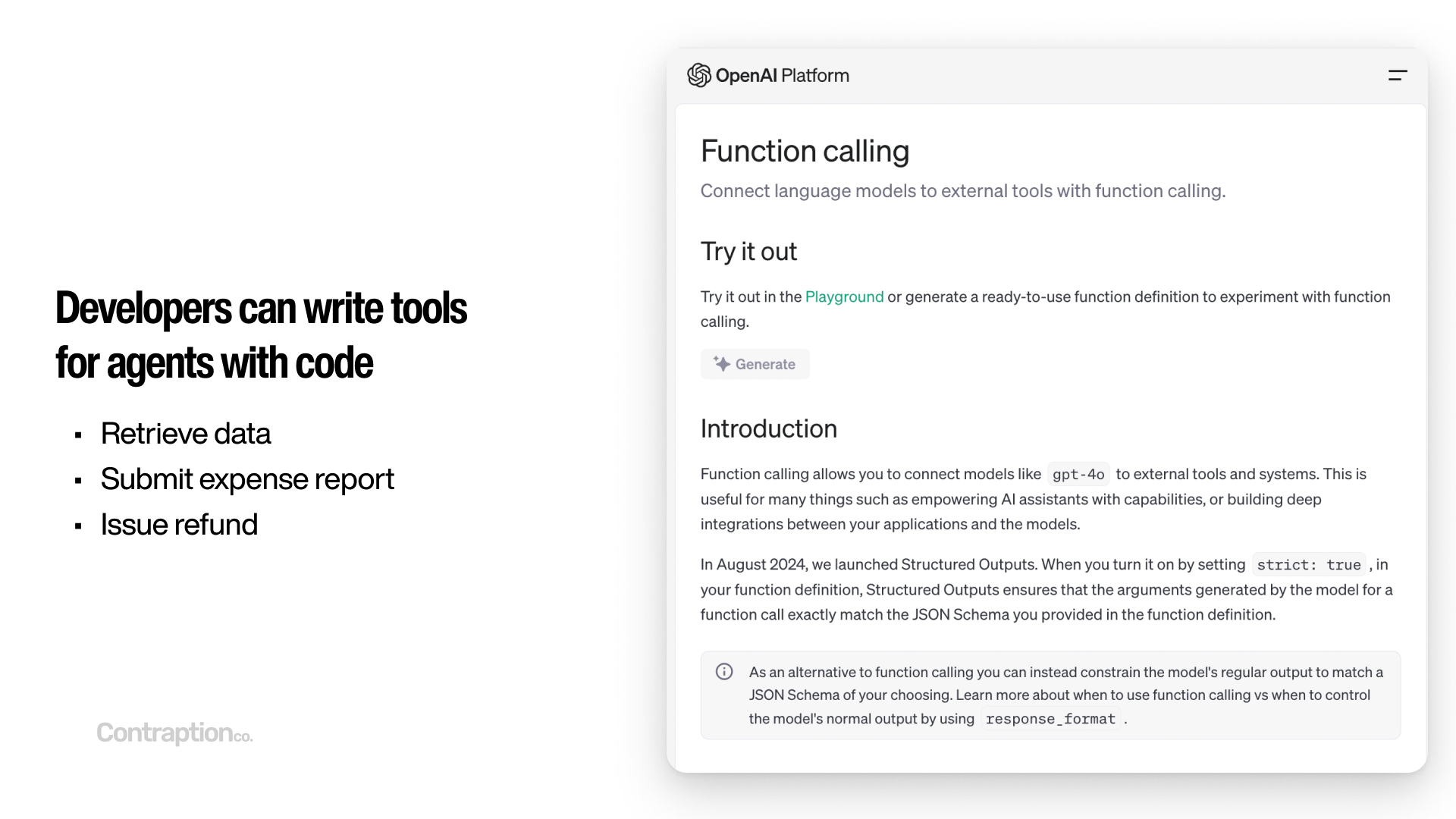
Developers can create tools for agents using code, enabling a wide range of functionalities—from retrieving data and submitting forms to processing refunds. These tools can incorporate user-specific context and include safeguards and limitations to ensure proper usage.
LLMS can now even interact with computers, extending their capabilities beyond traditional tasks. Robotic Process Automation (RPA) has long allowed developers to automate actions like browsing websites or performing operations. However, agents are taking this further. For instance, Anthropic’s new Computer Use feature gives LLMs a computer, allowing them to performing tasks such as web browsing, clicking buttons, and responding to error messages.
This advancement has significant implications. Compared to traditional RPA tools, agents are less fragile and far more adaptable, making them better suited to dynamic and complex workflows.

Agents represent the cutting edge of AI today, with startups equipping LLMs with a wide range of tools to tackle complex tasks. Veritas Labs is developing agents to automate healthcare operations and customer support. AiSDR has created a virtual salesperson that autonomously finds leads, sends emails, responds to customer inquiries, and schedules meetings. Meanwhile, Cognition AI has introduced Devin, touted as “the world’s first AI software engineer,” capable of accepting tasks and writing the code needed to complete them.
Agents are pushing the boundaries of LLM technology, enabling some of the first fully autonomous LLM applications.
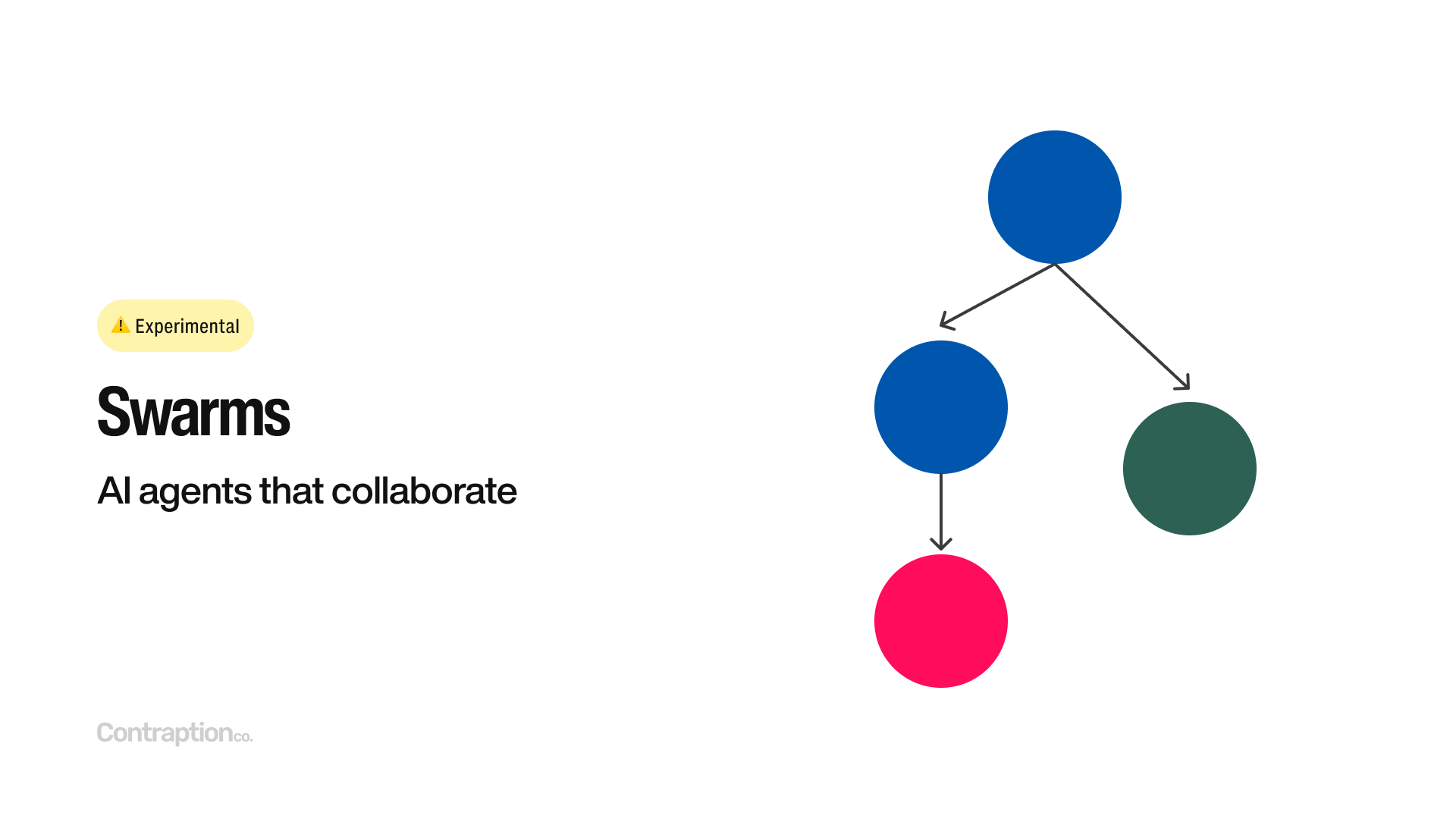
The final advanced application I want to discuss is the concept of Swarms—AI agents that collaborate to achieve a shared goal. OpenAI introduced this idea, along with the name, through an open-source project called “Swarm.” The core concept is to have a team of specialized AI agents that work together, each focusing on specific tasks.
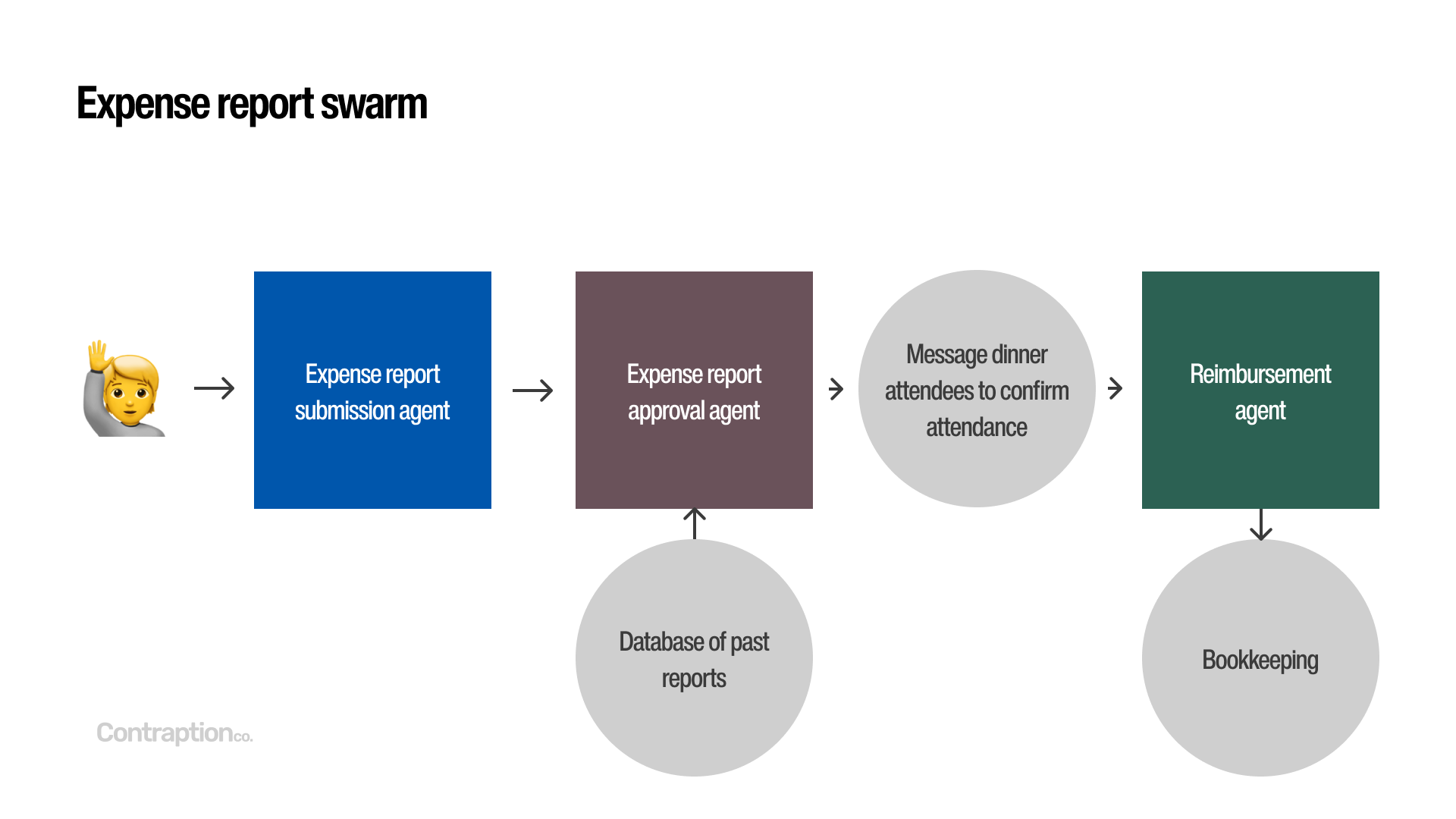
For example, imagine a swarm designed for handling expense reports. One agent could guide users through submitting expense reports, another could review and approve them by accessing relevant data (like past reports or messaging team members), and a third could handle reimbursements, including sending payments and updating bookkeeping. By dividing tasks among multiple agents, you can enhance safety and control—such as ensuring the expense review agent only processes documents and doesn’t access subjective information from the submitter.

Swarms represent the near future of generative AI applications. As agent platforms mature and standards for agent collaboration emerge, the adoption of swarms will likely become widespread, unlocking new possibilities for AI-driven workflows.

The goal of this presentation was to help you understand what people are actually doing with LLMs.

We covered building blocks, such as chat, embeddings, and semantic search. Then, we explored basic applications such as code generation, summarization, moderation, analysis, intent detection, and data labeling. Finally, we explored advanced applications - such as RAG, agents, and swarms.

Understanding the archetypes of LLM applications can help you identify opportunities to improve business processes and workflows with AI. Additionally, the discussion around hosted versus self-hosted solutions, along with potential vendors, should equip you to make informed decisions about when to build versus buy and how to evaluate the sophistication of various tools.
In software engineering, AI is already the present—not the future—and I believe we’ll see this same transformative impact extend across many other functions and industries. Thank you for taking the time to explore these ideas with me today.


